🚀 Portable does more than just ELT. Explore Our AI Orchestration Capabilities
Fivetran Custom Connectors: Your Best Alternatives In 2025

What Is a Fivetran Custom Connector?
Fivetran doesn't maintain custom connectors for clients. Instead, they offer a framework (via serverless functions) for you to build your own custom integration within a broader ETL framework. Or you can use their connector development capabilities.
At Portable, we build and maintain custom connectors for clients. We build them fast, and we're on-call when they break. That way, you can stay focused on what matters.
What Options Do You Have When Fivetran Is Missing a Connector?
You have 6 options when you need a connector that Fivetran doesn't support:
- Script an ETL data pipeline using a function connector.
- Find a data integration consultant that will handle replication for you. Luckily, we've pulled together a list of 175+ data consultants you can reach out to.
- Write code from scratch with your favorite programming language (Python is common). I'd recommend an orchestration tool like Airflow to help with scheduling.
- Use an open-source framework like Singer, Meltano, or Airbyte.
- Search for other data integration tools to see if they have a prebuilt connector you can use.
- Get started for free with Portable today.
How Do Fivetran Cloud Function Connectors Work?
Fivetran function connectors are data pipelines that you create for Fivetran to sync data on your behalf within a broader ETL framework.
There are a few steps in the process of building a new connector in this manner.
- Authorize
- Initial Sync
- Parse
- Process
- Load
- Update
You can dig deeper into the details, but the important thing to note is that as a developer, Fivetran has provided you with a template to organize your pipeline logic and metadata.
Do You Need To Read API Documentation To Develop a Fivetran Custom Connector?
Yes, for custom connectors, you have to read API documentation.
Unlike the Fivetran connectors in their directory, custom connectors are managed by clients. So you need to find the API documentation and then navigate the nuances of authentication, request and response structure, and pagination.
If you are a data engineer who is well versed in reading docs, handling HTTP codes, version control with GitHub, managing config files, identifying primary keys, processing JSON, and using cloud solutions like GCP or AWS, you’re probably set up to get started.
If this is new to you, here is an example of API documentation for the common CRM system HubSpot.
How Do You Navigate API Documentation To Build a Fivetran Custom Connector?
You need to understand the following concepts to navigate API documentation:
- Authentication - How do you authenticate with the API so they allow you to make requests? - Requests - Identify the endpoints you plan to make calls to, and research the format of how you need to make those requests. Are they REST APIs? GraphQL? Etc. - Responses - In what format is data returned from the API? How will your application process and store those responses? - Pagination - If you need to request multiple pages of data (i.e. the first 100 records, then the next 100), how do you do so? - Error handling - What could go wrong, and how will your system respond? - Rate limits - Many APIs don't want to be misused, so they restrict how frequently you can make requests. Are there rate limits in place, and how will your system respect them?
Do You Have To Write Code To Build a Fivetran Custom Connector?
Yes, you have to write code to build a custom integration within Fivetran.
Luckily, technologies like AWS Lambda, Azure Functions, and Google Cloud Functions remove the complexity of managing infrastructure, which can be a massive headache when building data infrastructure.
That being said, you still need to create an account with AWS, Azure, or Google Cloud, you need to get the data integration stood up, and then you need to convert your understanding of the API documentation into code that can run within a function.
What Logic Does Your Fivetran Custom Connector Include?
Your Fivetran custom connector code needs to include the following logic:
- Receive requests from Fivetran to initiate a sync
- Authenticate with an API key or other mechanism and make requests to the source system
- Receive and process the response from the API
- Return the response to Fivetran to load into your warehouse (Snowflake, BigQuery, Amazon Redshift, etc.)
How Do You Handle API Errors in Your Fivetran Custom Connector?
You need to write custom logic to understand the errors and address them programmatically.
Here is a list of the common HTTP error codes that you should consider.
While Fivetran doesn't help you to address the errors, or retry requests, they do offer the ability to expose errors into your Fivetran dashboard if you decide to add this logic to your function.
Does Fivetran Charge for Custom Connectors?
Yes. You have to pay Fivetran to move your data, and you have to pay the cloud charges associated with your custom ETL pipeline.
There are two major considerations around costs.
First, how much data are you processing? This matters not only because Fivetran offers pricing on monthly active rows, but also because data volume typically correlates closely with cloud compute costs for cloud functions.
Second, how efficient is your code to process the data? If your code is inefficient, it can cause your cloud bills to explode quickly at high data volumes. Even efficient code can lead to expensive cloud bills, but inefficiency can cause chaos.
It's always best practice to add maximum thresholds for billing to your cloud console and other safeguards. Why? There are certain death spirals around serverless functions that you don't want to end up in...
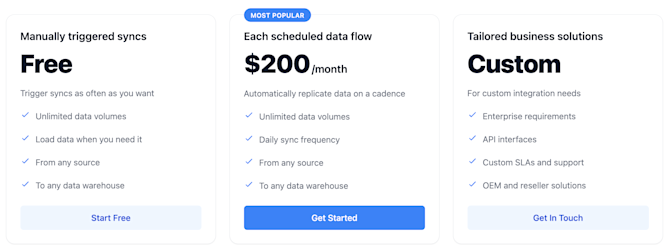
Portable keeps our pricing simple. Manual syncs are free, and recurring data flows are priced with a fixed cost each month.
Do You Have Any Other Options?
Yes. You have ONE other great option for custom integrations. Use Portable for a no code solution for custom connectors.
Clients with Fivetran in their data stack, and even resellers, commonly encounter use cases for custom integrations. Many of these companies trust Portable to build and maintain long-tail ETL connectors when Fivetran won't support them.
As a cloud-hosted SaaS solution just like Fivetran. Portable already supports 300+ hard-to-find data sources and loads the data into ready-to-query destination schemas.
Portable builds ETL connectors on-demand for clients. Development is free, and it's easy to sign up and manually sync data. Pricing is straightforward, and the Portable support team is on call if there are ever problems.
Want to spent your time writing SQL, managing models in DBT, building dashboards, and creating value from data?
How Do You Get Started With Portable for Custom Connectors?
Sign up, request a connector, or schedule time with me to learn more!
We work with plenty of happy Fivetran clients. You'll be in good hands.