🚀 Portable does more than just ELT. Explore Our AI Orchestration Capabilities
The Case for a Data Canvas

Over the past few years there has been an explosion of new tools providing data teams with functional solutions to build and maintain their data stack.
Snowflake provides easy, scalable storage, Portable and Fivetran bring disparate data sources together into one place, dbt gives us version control over our data models. Thanks to the modern data stack it has never been easier for a small team to create stable, scalable data pipelines. But there still remains a problem...
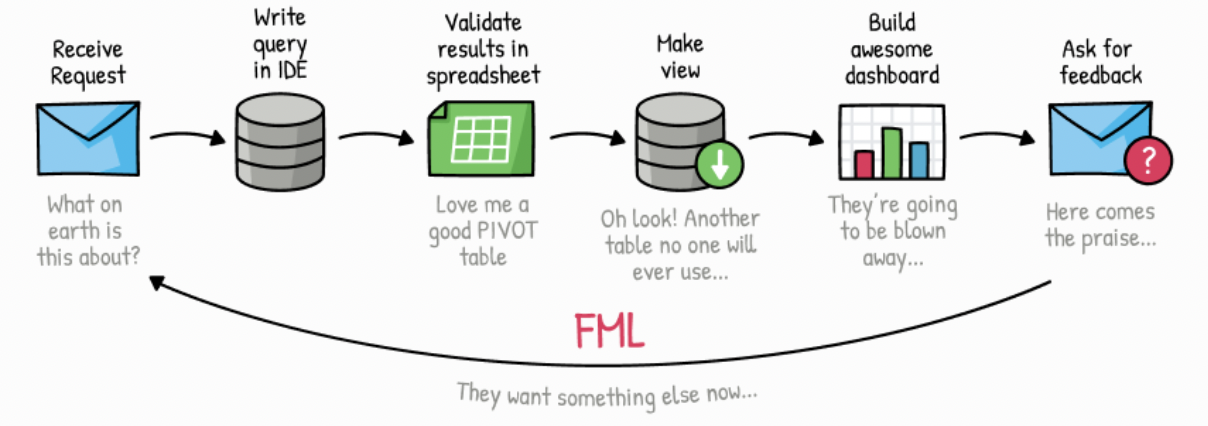
As data practitioners our workflow is terrible. Every day we drown in tabs as we hunt for "that" query; we cut and paste code between different tools as we jump around chasing a bug through our pipeline; we receive a never ending stream of requests from stakeholders asking us "for just another cut" to be added to their dashboard and we're constantly finding that "urgent" report never really gets used.
This problem isn't new, but it's arguably been getting worse. There's always a degree of cognitive load when completing a technical task but it gets harder as we now juggle our workflows across multiple tools across our data stacks.
Narrow function
Some complexity is hard to avoid. Valuable analyses are often complex and multi-faceted, a data model can have 100's of separate steps of logic which need to be understood individually and as a whole system. The question is whether the tools we use are helping us simplify this complexity or make it harder for us. I would argue that often it is the latter.
The challenge is that our data tools are optimized for a specific range of functions at the detriment of the wider workflow in which they sit.
As an example consider a typical SQL IDE. You have a big input box, a catalog of database artifacts to reference and an output preview. Perfect for helping you write a SQL query. But as soon as you start using your IDE for a wider goal (such as some exploratory queries or comparing the results of two different databases) its interface becomes a barrier and we start to sprout endless different tabs in our browser as we try and iterate through different query permutations.
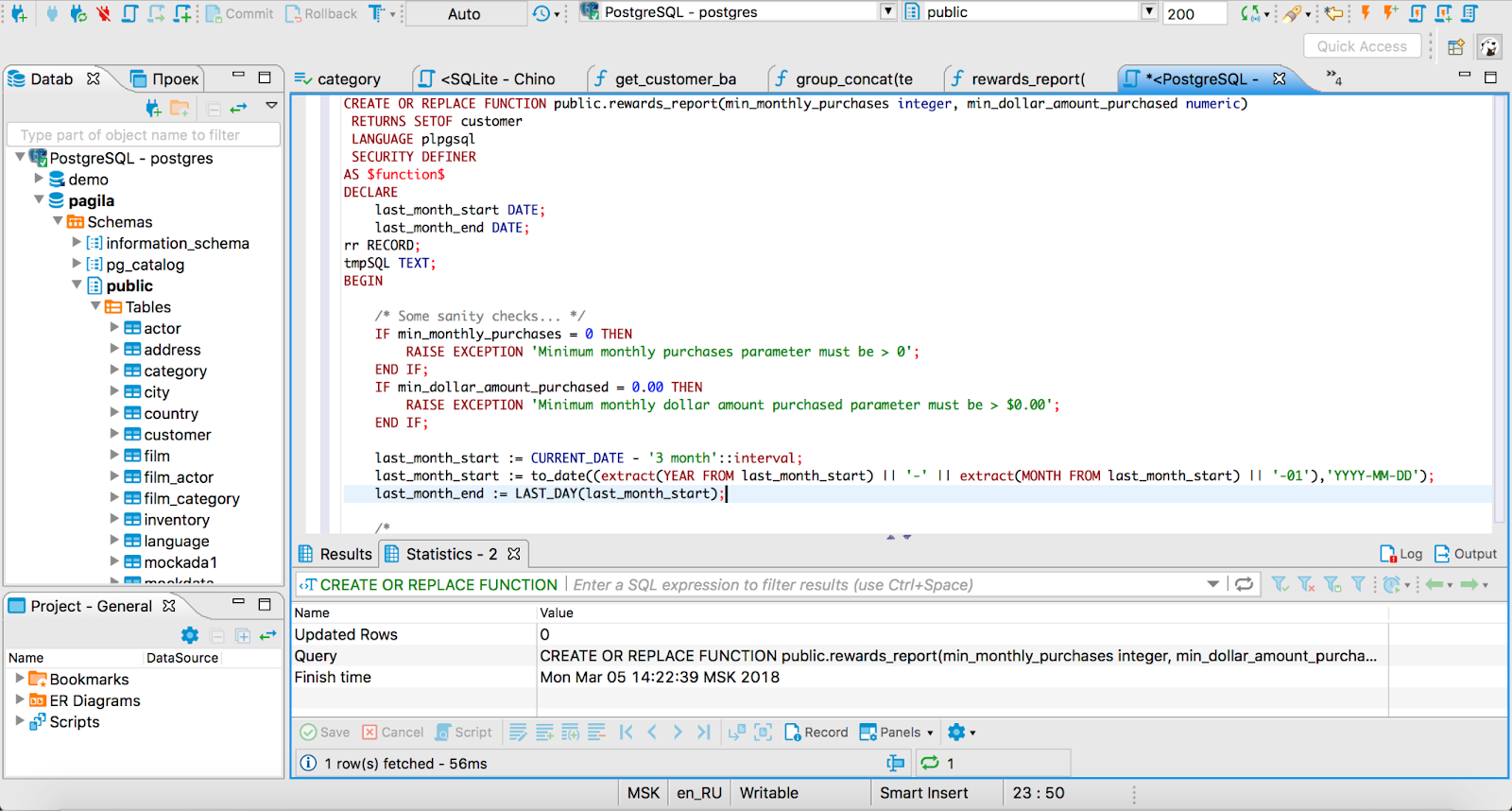
Similarly a dashboard is great at showing metrics, but it's terrible at supporting the wider discussion and decision those metrics are contributing too (hence why we cut and paste numbers out of dashboards into slide decks).
In both these cases the UI of these tools are not able to support the wider context in which they are being used, adding complexity to our workflow.
But there is another way...
Canvases => Freedom to think
Virtual canvas tools, such as Miro or Lucidchart, have become hugely popular in recent years as a way for remote teams to collaborate and problem solve together. They offer a flexible infinite space where ideas can be laid out spatially and discussed in real-time.
More recently the workflow benefits of the canvas interface have started being adopted in more specific domains of software such as Figma for design or Eraser for engineering and now the benefits of this way of working are becoming available to data teams too.
If you've ever valued the clarity of an entity relationship diagram you'll instantly see the benefits of this spatial way of working. Data as a discipline is inherently multi-disciplinary, requiring a combination of technical and problem solving skills, system design and amazing communication skills.
Data canvases aim to provide a space where all these skills can be blended together by combining the best elements of a SQL IDE, data notebook, BI tool and virtual whiteboard to support the end to end workflow of an analysis in a fully collaborative environment.
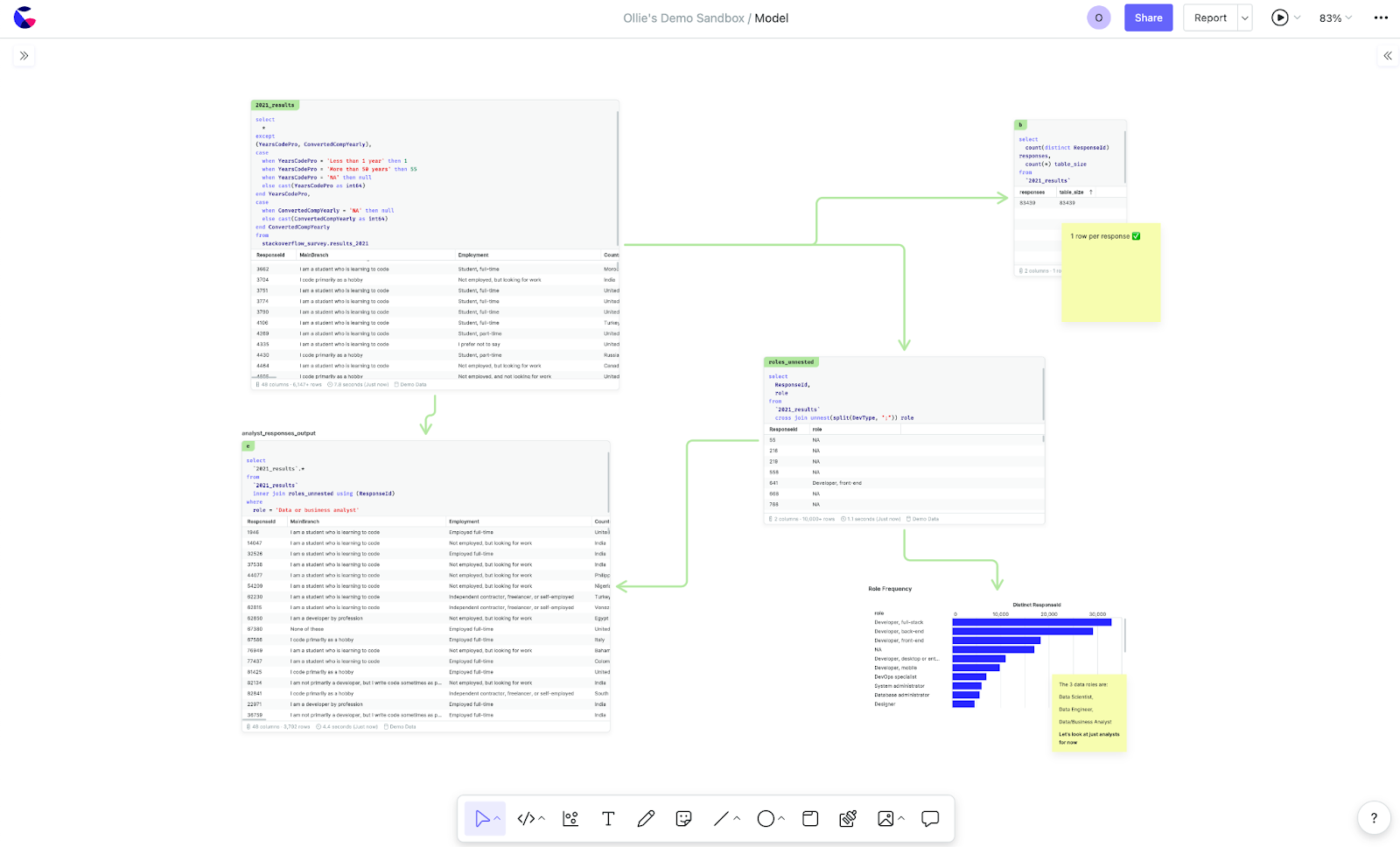
How a canvas improves data workflows
Let's review three examples for how the canvas improves the workflow for some core data tasks:
Data modeling
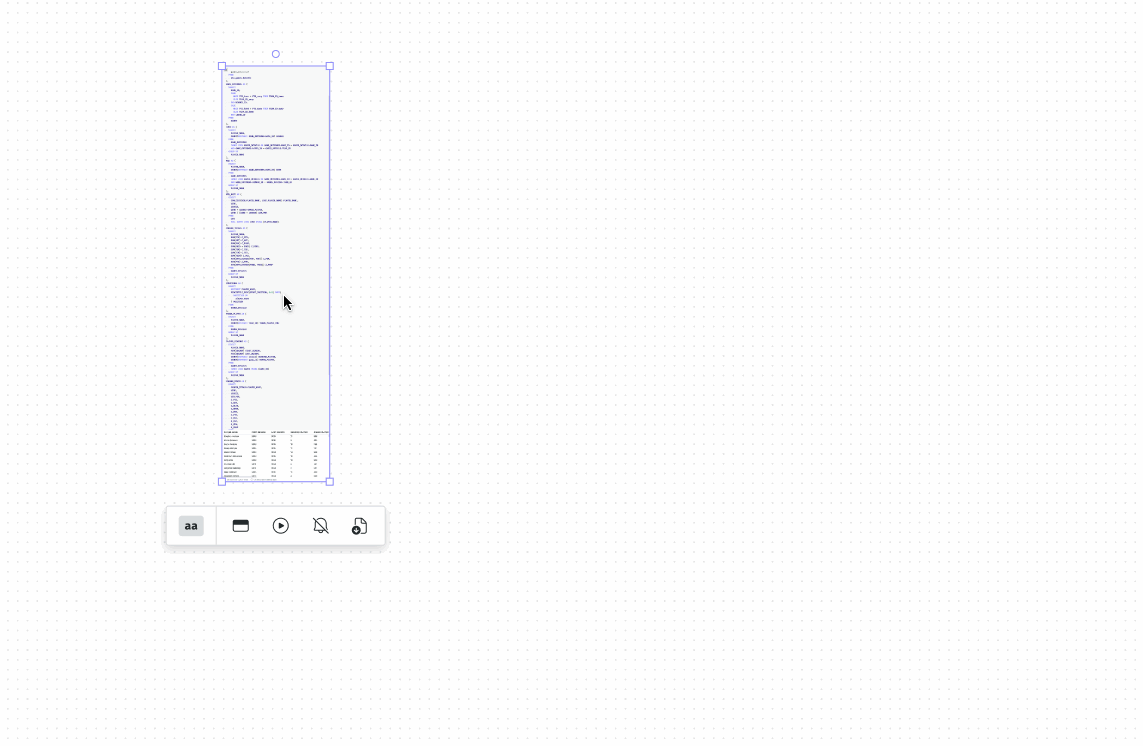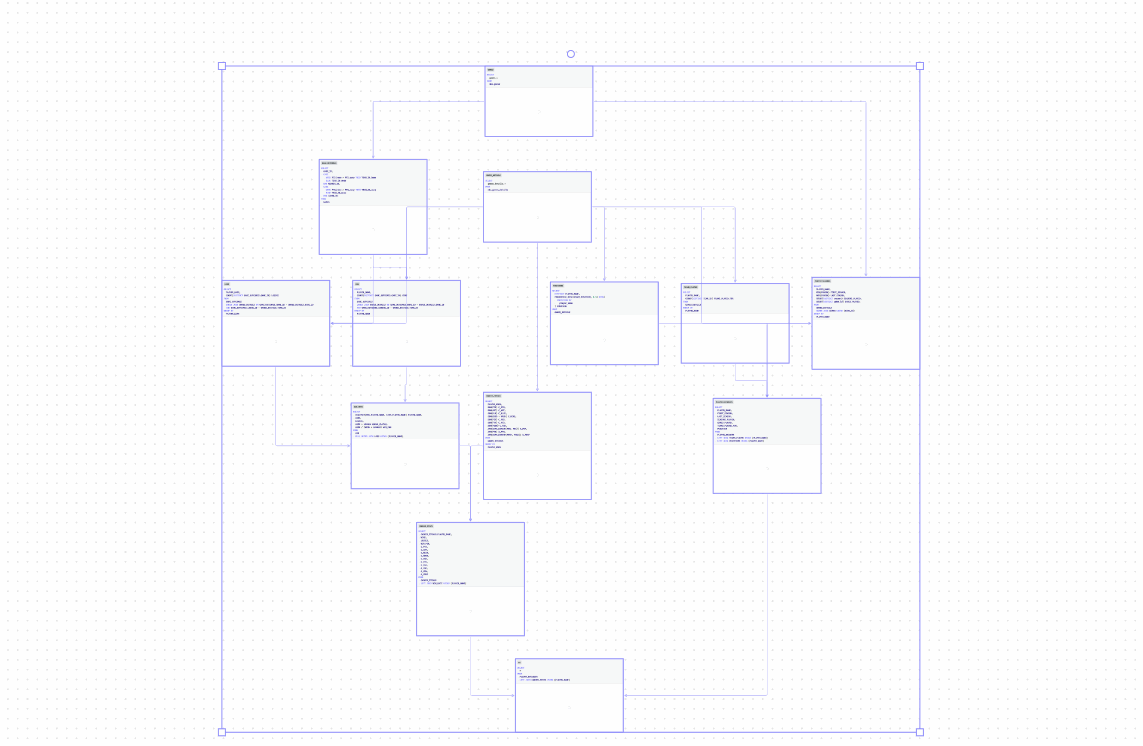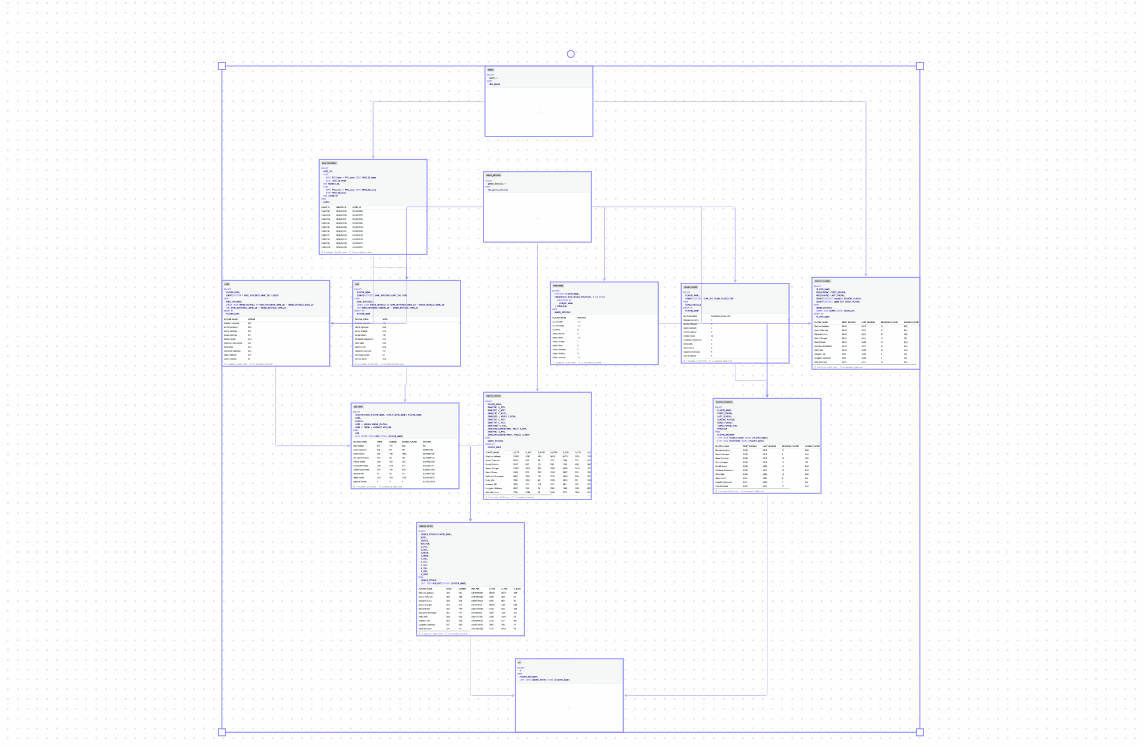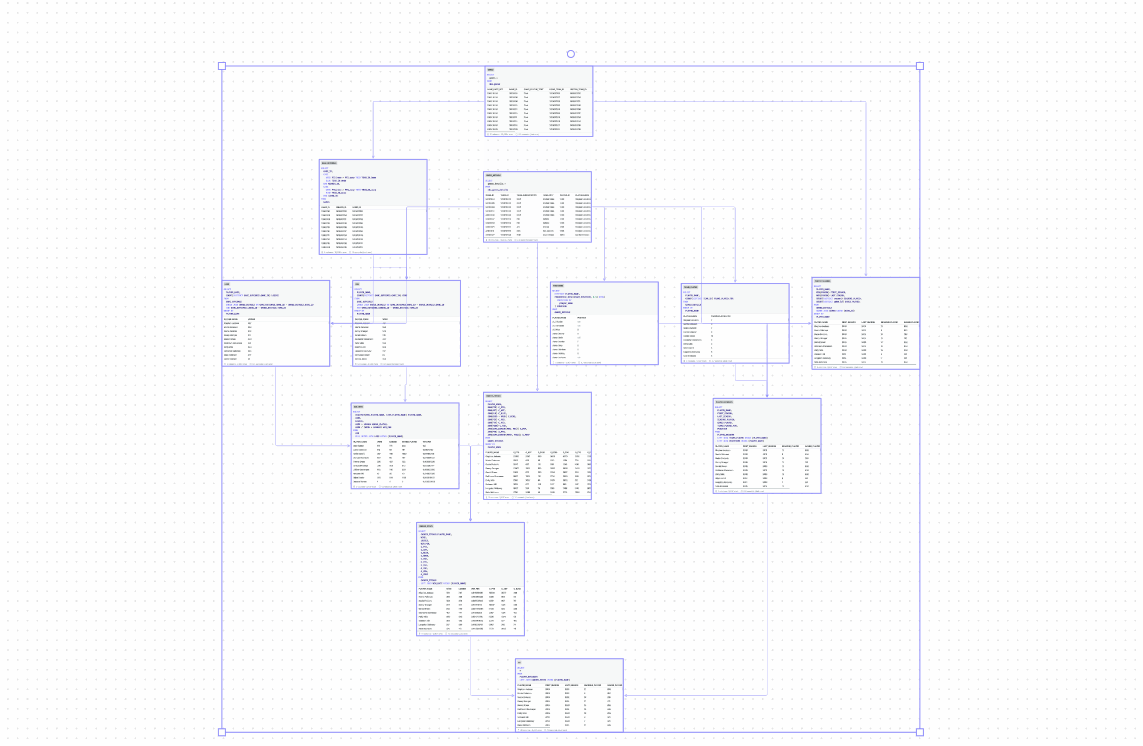
Reporting
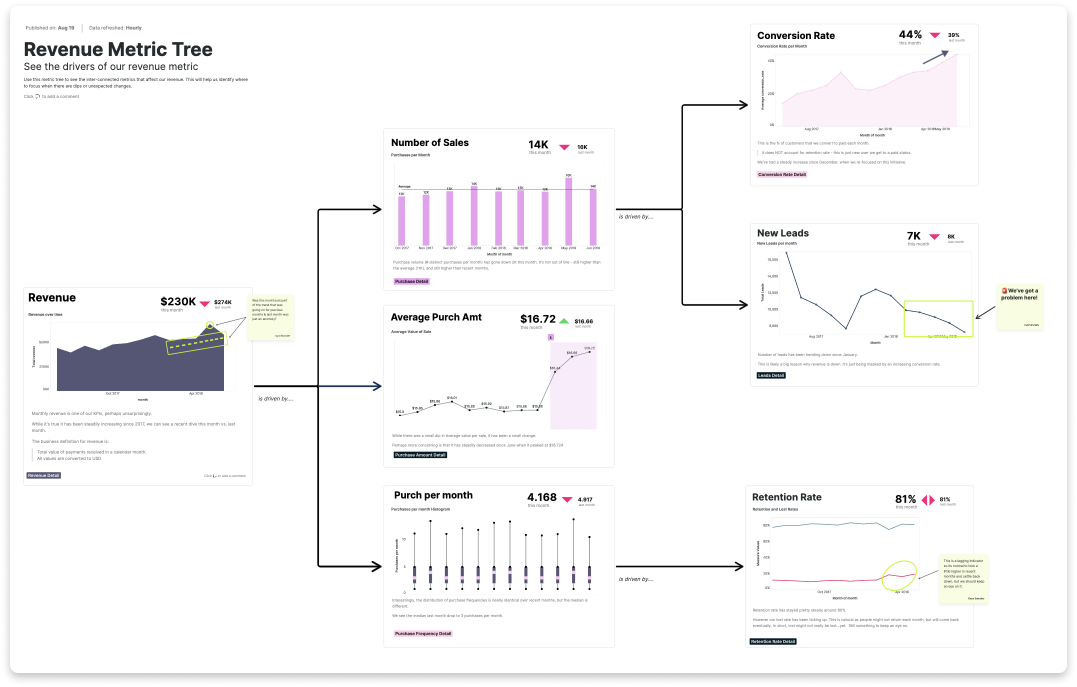
Problem solving
A data team's most valuable work comes when they are discovering something new. In conventional tools this kind of work has no real home. Insights are hard pasted into documents and the full picture is lost. In the canvas teams can lay out every aspect of their work from requirements gathering, gathering qualitative data, data exploration and final presentation in one place, making it easier to discuss, iterate and communicate.
The flexibility and collaborative nature of a data canvas completely changes the way data teams can work together and reduces the barriers for working with the wider organization. The modern data stack has allowed teams to deliver reliable data quickly, but the data canvas finally levels up the deliver mechanism for how this value is used.